Unsupervised Neural Machine Translation
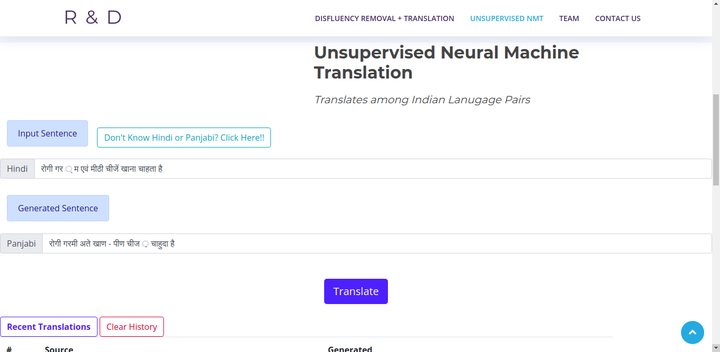
Progress in Unsupervised MT has been impressive where certain models are able to achieve performance near its supervised counterpart in particular settings. Unsupervised Neural Machine Translation performance relies on the intersection between the training and test datasets. The state-of-the art architectures fail on the real low-resource scenarios. Evaluating current UNMT architectures on truly low-resource datasets shows that it struggles in realistic scenarios. It is an open question that the three pillars of unsupervised MT are sufficient and necessary or there is a need of more? In this work, we found out that the current UNMT models fail when the datasets are dissimilar amongst Indian language pairs. It is highly encouraged to do extensive evaluation of these architectures in all broad data scenarios and opening pursuits for research in each one of them.