Learn to Unlearn in Large Language Models
Abstract
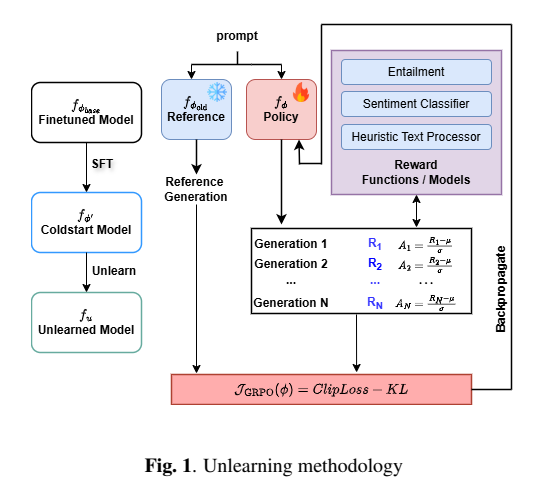
Large Language Models are trained on massive corpora, allowing them to acquire extensive linguistic and factual knowledge. The training data often contains sensitive and copyrighted information, leading to concerns about unintended memorization and privacy leakage. Model unlearning aims to remove the influence of specific data without compromising model performance or general knowledge. We introduce a novel unlearning framework based on reinforcement learning, leveraging Group Relative Policy Optimization to effectively forget sensitive content. We deploy a two-stage approach starting with cold-start fine-tuning using curated synthetic data to initialize the model. We introduce carefully designed reward functions, combining lightweight models and heuristics, to guide the unlearning process while maintaining computational efficiency in RL training. Extensive experiments on the TOFU dataset show that our method outperforms prior unlearning approaches, achieving a 47% model utility improvement and 0.023 ROUGE on forget set while retaining performance on retain set and mitigating hallucinations.